python数据结构
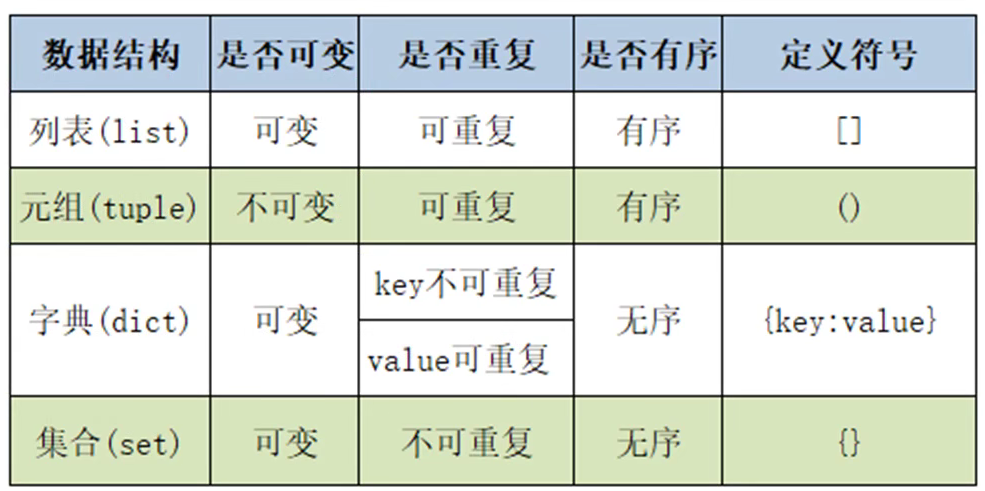
各种数据结构区别
列表
列表相当于c中的数组,不过python的列表对每个元素没有同一类型要求,索引从0开始,也可以从后面-1开始, 以[]表示
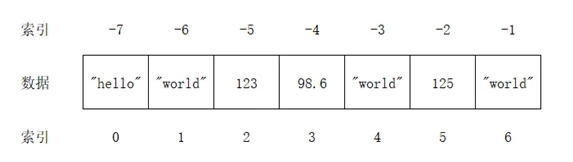
列表是动态分配内存的
1 | lst=['hello', 'world' , 98] |
输出
1 | 000000000000 |
列表的创建可以直接赋值,或者使用list()函数
元素的索引
index()函数,查找元素的索引,如果有相同只返回第一个
1 | list.index('') |
获取列表的切片
1 | #列表名[ start : stop : step ] |
切出来是一个新的列表对象
列表的遍历
for 迭代变量 in 列表条:
操作
列表元素的增、删、改
1 | lst.append()#增加后还是原来的列表,把对象作为一个对象添加 |
列表元素的排序
1 | lst.sort()#升序排列,对原对象进行操作 |
列表推导式
1 | list=[i*i for i in range(1,10)] |
表达式 for 变量 in 可迭代对象
字典
以花括号表示{},是python的内置数据结构
字典内以键值对存储(key,vaule),无序排列

字典的创建
使用花括号
scores={ “1’: 1, ‘2’ : 2 }
使用内置函数dict()
dict( name=’ ’ , age=1 )
字典元素的获取
[“”]用花括号获取,如果查不到会报错
用get()方法 ,查不到返回null
1 | get('张三') |
字典元素的增删改操作
del删除
clear()清空
keys()获取字典中所有key
values()获取字典中所有value
items() 获取字典中所有key,value对
items转换之后的列表元素是由元组组成
字典元素的遍历
1 | for item in scores: |
字典生成式
1 | { item:price for item,price in zip(items,prices)} |
字典表达式 字典变量 可迭代对象
元组
不可变序列,没有增删改查操作,使用小括号()
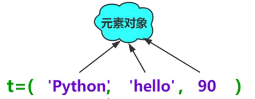
元组创建
直接创建,可省略小括号
t=( ‘Python; ‘hello’, 90 )
内置函数tuple()
t= tuple( (‘Python’, ‘hello’ , 90) )
只包含一个元组的元素需要使用逗号和小括号
t=( 10,)
元组遍历
1 | for item in t: |
集合
可变类型的序列,没有vaule的字典,用{}花括号,集合中的元素不允许重复
集合创建
直接{}
s={ ‘Python’ , ‘hello’}
使用内置函数set()
1 | s= set(range(6)) |
集合操作
集合元素的判断操作in或not in
集合元素的新增操作
add()方法,一次添中一个元素
update()方法,添中多个元素
集合元素的删除操作
remove()方法,一次删除一个指定元素,指定的元素不存在抛出异常
discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛出异常
pop()方法,一次只删除一个任意元素
clear()方法,清空集合
关系运算
集合也能进行关系运算
两个集合是否相等
可以使用运算符==或!=进行判断
一个集合是否是另一个集合的子集issubset
一个集合是否是另一个集合的超集issuperset
两个集合是否有交集isdisjoint()
集合数学操作
交集 intersection() &
并集 union() |
差集 difference() -
对称差集 symmetric_difference() ^
a并b-a交b
集合生成式
1 | list={i*i for i in range(1,10)} |
字符串
字符串驻留机制
python中的字符串,只保留一份拷贝,声明相同的字符串,不会创建新内存空间
驻留机制的几种情况
- 字符串的长度为0或1
- 符合标识符的字符串(不符合的不会驻留,比如加上%)
- 字符串只在编译时进行驻留,而非运行时
- [-5,256]之间的整数数字
在拼接时建议使用str类型的join方法,而非+ ,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率比”+”效率高
常用操作
查询
| 方法 | 作用 |
|---|---|
| index() | 查找子串第一次出现的位置,不存在抛出异常 |
| rindex() | 查找子串最后一次出现的位置,找不到抛出异常 |
| find() | 查找子串第一次出现的位置,不存在时返回-1 |
| rfind() | 查找子串最后一次出现的位置,子串不存在时返回-1 |
大小写转换
| 方法 | 作用 |
|---|---|
| upper() | 转成大写 |
| lower() | 转成小写 |
| swapcase() | 大写转成小写,小写转大写 |
| capitalize() | 第一个字符转换为大写,把其余字符转换为小写 |
| title() | 把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写 |
对齐
| 方法 | 作用 |
|---|---|
| center() | 居中对齐,第1个参数指定宽度,第2个参数指定填充符(可选),默认空格 |
| ljust() | 左对齐,第1个参数指定宽度,第2个参数指定填充符(可选),默认空格 |
| rjust() | 右对齐,第1个参数指定宽度,第2个参数指定填充符(可选),默认空格 |
| zfill() | 右对齐,左边用0填充,有一个参数,指定字符串的宽度 |
分割
| 方法 | 作用 |
|---|---|
| split() | 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回一个列表 |
| rsplit() | 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回一个列表 |
| 参数 sep 指分割符 maxsplit 指定最大分割次数 在最大次劈分之后,剩余子串单独做为一部分 |
判断
| 方法 | 作用 |
|---|---|
| isidentifier() | 是否合法 |
| isspace() | 是否全部由空白字符组成(回车、换行,水平制表符) |
| isalpha() | 是否全部由字母组成 |
| isdecimal() | 是否全部由十进制的数字组成 |
| isnumeric() | 是否全部由数字组成 |
| isalnum() | 是否全部由字母和数字组成 |
替换
| 方法 | 作用 |
|---|---|
| replace() | 参数 第一个,指定被替换的子串 第二个,指定替换子串的字符串 第三个,指定最大替换次数 |
| join() | 将列表或元组中的字符串合并成一个字符串 |
字符串的比较
可以进行>,>=,<,<=,==,!=运算
比较规则
先比较第一个,若相等就往后比;如果不同时,比较字符的ascall值,返回true或false
==比较的是值,is比较的是内存地址
字符串的切片
切片会产生新的内存
语法[start : end::step]
步长可以省略
1 | s='hello,python' |
格式化字符串
百分号%
1 | name='张三' |
花括号{}
1 | print ('我叫{0},今年{1}岁'.format(name, age)) |
f格式化(python3以上)
1 | print(f'我叫{name},今年{age}岁') |
精度
1 | print(’%10d’% 99)#10表示的是宽度 |
字符串的编码转换
1 | #编码 |